El otro día recibí la pregunta que si en el momento que hago commit, los datos los encuentro en los datafiles?
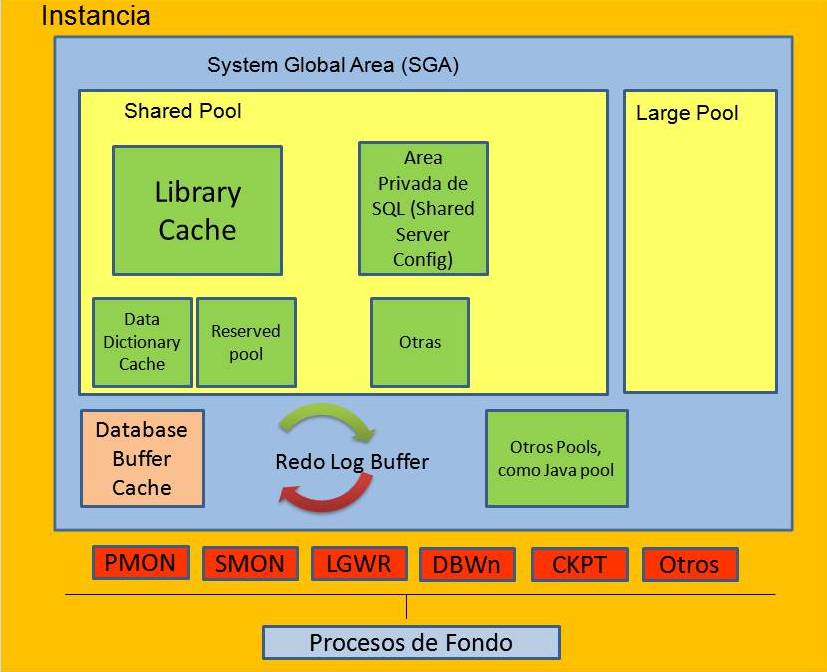
Para poder entender esta pregunta, primero debemos conocer un poco los procesos y las estructuras de memoria que tiene Oracle, te invito a que vayas a la entrada
Instancia es igual a procesos y memoria para que tengas una mejor idea de varios de los procesos que vamos a hablar aqui.
Lo primero que hay que entender es que el
DBWn es un proceso flojo,ya que no es un proceso que cada n segundos este escribiendo los datos del Buffer Cache a los datafiles, si no que es activado por otro proceso (Como
CKPT por ejemplo).
Tomemos el siguiente ejemplo,supon que yo siendo el todopoderoso, incremento mi salario de 1 USD a 5 USD en la tabla employees, e inmediatamente despues hago un commit.
Pregunta, si yo ya hice un commit, encontraría el valor de 5 USD en los datafiles?
Antes de responder esta pregunta, vamos a poner otra situación con el mismo ejemplo, en lugar de cometer mis datos después del incremento salarial que me di,decido esperarme el fin de semana para reflexionar en este cambio, solamente dejo la sesión abierta sin cometer los datos.
El lunes que regreso, y verifico los datos directamente en los datafiles, que valor encontraría, 1 o 5 USD?
La lógica me llevaría a decir que, 1 USD, ya que nunca cometí mis datos, cierto?
Una ultima pregunta con este escenario,acuerdate que no hemos cometido los datos,si yo checara los datos en el Online Redo Log, que valor encontraria, 1 o 5 USD?
Si tu respuesta fue 1 USD, seria la mas lógica, ya que no he cometido los datos y no son necesarios para el proceso de recuperación en caso de que mi base de datos se cayera, si respondiste 5 USD, entonces como explicarías el proceso de recuperación en caso de que se haya caído la instancia, si cuando se hace una recuperación los procesos leen del Online Redo Log, y el valor que se encuentra es el de 5 USD?
Antes de empezar, y para que no se te quemen las habas,las respuestas son 1,5 y 5 USD
Vamos a tratar de explicarlo aquí abajo
Crea un tablespace pequeño, en este casa de 1M, y crea en el usuario hr, una tabla llamada prueba_salario, y en esta tabla inserta el dato de salario
TESTDB >create tablespace prueba datafile '/mount/u01/oracle/TESTDB/data/pruebas01.dbf' size 1m;
Tablespace created.
TESTDB >create table hr.prueba_salario (salario varchar2(200)) tablespace prueba;
Table created.
TESTDB >insert into hr.prueba_salario values ('1_USD');
1 row created.
TESTDB >commit;
Commit complete.
Una vez que completes esto, recicla la base de datos, ya que no queremos que nada se encuentre en memoria, y si te fijas, el dato de 1_USD lo puedes ver
en el datafile
oracle@localhost [TESTDB] /mount/u01/oracle/TESTDB/data
root $ strings /mount/u01/oracle/TESTDB/data/pruebas01.dbf
z{|}
5wXTESTDB
PRUEBA
1_USD
Y ahora haz un update a la tabla hr.prueba_salario y realiza un commit, inmediatamente después verifica de nuevo el datafile, y te vas a dar cuenta
que este dato que acabas de actualizar no se encuentra en el datafile, que sigues viendo el valor de 1_USD
TESTDB >update hr.prueba_salario set salario = '5_USD';
1 row updated.
TESTDB >commit;
Commit complete.
oracle@localhost [TESTDB] /mount/u01/oracle/TESTDB/data
root $ strings /mount/u01/oracle/TESTDB/data/pruebas01.dbf
z{|}
5wXTESTDB
PRUEBA
1_USD
En el momento que mandamos llamar al proceso de CKPT, es cuando los buffers "sucios" se escriben a disco, despues de que hagas un checkpoint,
verifica de nuevo el datafile, y te vas a dar cuenta que el datafile esta actualizado con el nuevo valor de 5_USD.
TESTDB >alter system checkpoint;
System altered.
oracle@localhost [TESTDB] /mount/u01/oracle/TESTDB/data
root $ strings /mount/u01/oracle/TESTDB/data/pruebas01.dbf
z{|}
5wXTESTDB
PRUEBA
5_USD
Ahora vamos a hacer otra prueba, tira la tabla prueba_salario, vuelvela a crear, vuelve a insertar el dato de 1_USD y una vez que finalices esto, recicla la base de datos para asegurarnos que no se encuentre nada en memoria.
Ahora vamos a hacer un update a la tabla de prueba salario, y no vamos a hacer un commit, solamente vamos a llamar al proceso de
CKPT.
TESTDB >update hr.prueba_salario set salario = '5_USD';
1 row updated.
TESTDB >alter system checkpoint;
System altered.
Si te fijas abajo, el dato de 5_USD es el que se encuentra en el datafile y no el de 1_USD, aunque no hemos hecho un commit de los datos.
oracle@localhost [TESTDB] /mount/u01/oracle/TESTDB/data
root $ strings /mount/u01/oracle/TESTDB/data/pruebas01.dbf
z{|}
5wXTESTDB
PRUEBA
5_USD
Abre una nueva sesión y haz un query a la tabla y te fijaras que el dato de 1_USD es el que te arroja, que es el correcto ya que no hemos cometido los datos
TESTDB >select * from hr.prueba_salario;
SALARIO
------------------------
1_USD
Una de las preguntas que te has de estar haciendo en este momento, es como Oracle sabe que información arrojar, si en el datafile se encuentra el valor de 5_USD. Oracle logra esto a través de un flujo que se llama Consistencia de Lectura (
Read Consistency [
RC]).
Antes de continuar hay que conocer que es el
SCN (
System
Change
Number), este es el punto logico
en el tiempo en el que los cambios se hacen a la base de datos.
El flujo de
RC funciona con el
SCN para garantizar el orden de las transacciones, cuando lanzaste el query en la sesión nueva, la base de datos determina el
SCN registrado en el momento que el query se empezó a ejecutar.
Este select requiere una versión de los bloques de datos que sean consistentes con los cambios que únicamente se encuentran cometidos. Oracle copia los bloques que se encuentran en los bloques actuales a un buffer de datos nuevo y le aplica datos de undo para reconstruir las versiones anteriores de los bloques de datos. A estas copias se le conocen como clones de consistencia de lectura(Consistency Read Clones).
Para saber si la transaccion esta cometida o no, Oracle utiliza una tabla de transacciones llamada lista de transacciones de interes (
Interested
Transaction
List [
ITL]), esta lista se encuentra en la cabecera del bloque.
Para terminar y regresar al punto, si sabemos que el
DBWn es un proceso flojo, y que aunque haga un commit de mis datos, estos pueden que no se encuentren en los datafiles.
¿De donde toma Oracle la información para esto si se me llegara a caer la base de datos antes de que el
CKPT mandara a llamar al
DBWn?
La respuesta esta en el
Online Redo Log y cuando encuentra el marcador de commit, como ya habíamos platicado de lo
que es el Online Redo Log, no voy a entrar mas a detalle en este tema, pero como puedes ver por los ejemplos anteriores, el
Online Redo Log, es critico para la consistencia de nuestros
datos.
Conclusion
Espero que con esta explicación puedas comprender la importancia de los
Online Redo Logs, ya que si los llegaras a perder, puedes tener perdida de información en tu base de datos, también vimos un poco de como funciona el undo y como se logra la consistencia de lectura a través de sesiones sin cometer.
P.D. Quiero Agradecer a
Arup Nanda por permitirme utilizar gran parte de su material para esta entrada,
100 Things You Probably Didn't Know.
Actualización
04/Dec/2012: No me habia fijado que el formato de SQL de esta entrada se habia perdido, asi que se lo volvi a poner.